![]()
![]()
![]()
![]()
|
Escalabilidad Horizontal |
|||||
|
La escalabilidad horizontal consiste en potenciar el rendimiento del sistema desde un aspecto de mejora global, a diferencia de aumentar la potencia de una única parte del mismo. Este tipo de escalabilidad se basa en la modularidad de su funcionalidad. Por ello suele estar conformado por una agrupación de equipos que dan soporte a la funcionalidad completa. Normalmente, en una escalabilidad horizontal se añaden equipos para dar mas potencia a la red de trabajo.
Con un entorno de este tipo, es lógico pensar que la potencia de procesamiento es directamente proporcional al número de equipos de la red. El total de la potencia de procesamiento es la suma de la velocidad física de cada equipo transferida por la partición de aplicaciones y datos extendida a través de los nodos.
Si se aplica un modelo d
El encargado de como realizar el modelo de partición de datos en los diferentes equipos es el desarrollador conjuntamente con el jefe o director del proyecto, funciona llevaba a cabo por un ingeniero en sistemas o licenciado en sistemas.
Existen dependencias en el acceso a la aplicación. Es conveniente, realizar una análisis de actividad de los usuarios para ir ajustando el funcionamiento del sistema. Con este modelo de la escalabilidad, se dispone de un sistema al que se pueden agregar recursos de manera casi infinita y adaptable al crecimiento de cargas de trabajo y nuevos usuarios.
La escalabilidad cuenta como factor crítico el crecimiento de usuarios. Es mucho más sencillo diseñar un sistema con un número constante de usuarios (por muy alto que sea este) que diseñar un sistema con un número creciente y variable de usuarios. El crecimiento relativo de los números es mucho más importante que los números absolutos.
A la hora de diseñar un sistema con comparición de recursos, es necesario considerar como balancear la carga de trabajo. Se entiende este concepto, como la técnica usada para dividir el trabajo a compartir entre varios procesos, ordenadores, u otros recursos. Esta muy relacionada con lo sistemas multiprocesales, que trabajan o pueden trabajar con mas de una unidad para llevar a cabo su funcionalidad. Para evitar los cuellos de botella, el balance de la carga de trabajo se reparte de forma equitativa a través de un algoritmo que estudia las peticiones del sistema y las redirecciona a la mejor opción.
Presenta las siguientes características:
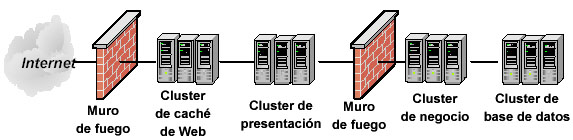
El concepto de clustering introduce la capacidad de unir varios servidores para que trabajen en un entorno en paralelo. Es decir, trabajar como si fuera un solo servidor el existente. En las etapas primigenias del clustering, los diseños presentaban graves problemas que se han ido subsanando con la evolución de este campo. Actualmente se pueden crear clusters en función de las necesidades.
En resumen, cluster es un grupo de múltiples ordenadores unidos mediante una red de alta velocidad, de tal forma que el conjunto es visto como un único equipo, más potente. Con ello se pretende mejorar los siguientes parámetros de la arquitectura:
El clustering no presenta dependencias a nivel de hardware (no todos los equipos necesitan el mismo hardware) ni a nivel de software (no necesitan el mismo sistema operativo). Este tipo de sistemas dispones de una interfaz que permite dirigir el comportamiento de los clusters. Dicha interfaz es la encargada de la interactuación con usuarios y procesos, realizando la división de la carga entre los diversos servidores que compongan el cluster.
Alta Disponibilidad (HA) y Failover. Enfocados a garantizar un servicio ininterrumpido, al duplicar toda la infraestructura e introducir sistemas de detección y re-enrutamiento (Servicios Heart-Beat), en caso de fallo. El propósito de este tipo de clusters es garantizar que si un nodo falla, los servicios y aplicaciones que estaban corriendo en ese nodo, sean trasladados de forma automática a un nodo que se encuentra en stand-by. Este tipo de cluster dispone de herramientas con capacidad para monitorizar los servidores o servicios caídos y automáticamente migrarlos a un nodo secundario para garantizar la disponibilidad del servicio. Los datos son replicados de forma periódica, o a ser posible en tiempo real, a los nodos en Stand-by
Cluster Balanceado. Este tipo de cluster es capaz de repartir el tráfico entrante entre múltiples servidores corriendo las mismas aplicaciones. Todos los nodos del cluster pueden aceptar y responder peticiones. Si un nodo falla, el tráfico se sigue repartiendo entre los nodos restantes.
|
 e escalabilidad basado en la horizontalidad, no
existen limitaciones de crecimiento a priori. Como principal e
importante defecto, este modelo de escalabilidad supone una gran
modificación en el diseño, lo que conlleva a una gran trabajo de diseño
y reimplantación. Si la lógica se ha concebido para un único servidor,
es probable que se tenga que estructurar el modelo arquitectónico para
soportar este modelo de escalabilidad.
e escalabilidad basado en la horizontalidad, no
existen limitaciones de crecimiento a priori. Como principal e
importante defecto, este modelo de escalabilidad supone una gran
modificación en el diseño, lo que conlleva a una gran trabajo de diseño
y reimplantación. Si la lógica se ha concebido para un único servidor,
es probable que se tenga que estructurar el modelo arquitectónico para
soportar este modelo de escalabilidad.

![]()
*